Рождение советской ПРО. «Эль-Берроуз»

Бурцев унаследовал от своего учителя любовь и уважение к западным прототипам, да, в принципе, начиная с БЭСМ-6 ИТМиВТ активно обменивался информацией с Западом, в основном с IBM в США и Манчестерским университетом в Англии (именно эта дружба и заставляла Лебедева в т. ч. лоббировать интересы британской ICL, а не немецкого Robotron на том памятном совещании в 1969 году).
Естественно, у «Эльбруса» не могло не быть прототипа, и сам Бурцев признает это открытым текстом.
Ответ однозначный: «Да». Перед тем, как начинать проектировать новую ЭВМ, мы всегда очень внимательно изучали разработки всего мира в этой области.
В те времена встал вопрос о повышении уровня машинного языка, с тем чтобы уменьшить разрыв между языком высокого уровня и командным с целью увеличения эффективности прохождения программ, написанных на языке высокого уровня.
В этом направлении в мире работали в трех местах.
В теоретическом плане наиболее сильной была работа Айлифа: «Принципы построения базовой машины», в Манчестерском университете в лаборатории Килбурна и Эдвардса была создана машина МU-5 («Манчестерский университет-5»), а в фирме Барроуз разрабатывались машины для банков и военных применений.
На всех трех фирмах я был, беседовал с основными разработчиками и имел необходимые материалы по принципам, заложенным в эти разработки.
При проектировании МВК «Эльбрус-1» и «Эльбрус-2» мы брали из передовых разработок все, что нам представлялось стоящим. Так делаются и должны разрабатываться все новые машины.
На разработку МВК «Эльбрус-1» и «Эльбрус-2» оказали влияние архитектуры и НР, и 5Э26, и БЭСМ-6, и ряд других разработок того времени».
В те времена встал вопрос о повышении уровня машинного языка, с тем чтобы уменьшить разрыв между языком высокого уровня и командным с целью увеличения эффективности прохождения программ, написанных на языке высокого уровня.
В этом направлении в мире работали в трех местах.
В теоретическом плане наиболее сильной была работа Айлифа: «Принципы построения базовой машины», в Манчестерском университете в лаборатории Килбурна и Эдвардса была создана машина МU-5 («Манчестерский университет-5»), а в фирме Барроуз разрабатывались машины для банков и военных применений.
На всех трех фирмах я был, беседовал с основными разработчиками и имел необходимые материалы по принципам, заложенным в эти разработки.
При проектировании МВК «Эльбрус-1» и «Эльбрус-2» мы брали из передовых разработок все, что нам представлялось стоящим. Так делаются и должны разрабатываться все новые машины.
На разработку МВК «Эльбрус-1» и «Эльбрус-2» оказали влияние архитектуры и НР, и 5Э26, и БЭСМ-6, и ряд других разработок того времени».
Итак, Бурцев, в отличие от многих, признает, что не стеснялся щедро заимствовать архитектурные идеи у соседей и даже говорит, где поискать хвосты.
Давайте воспользуемся щедрым предложением и копнем три источника и три составные части «Эльбруса».

Первая – это монография Джона Айлифа (John Kenneth Iliffe) Basic Machine Principles (Macdonald & Co; 1st edition, January 1, 1968) и его же статья Elements of BLM (The Computer Journal, Volume 12, Issue 3, August 1969, Pages 251–258), вторая – это практически неизвестный компьютер M.U.5, построенный как эксперимент в Манчестерском университете, и третий – Burroughs 700-й серии.
А не клон ли сам Burroughs?
Начнем разбираться по порядку.
Во-первых, некоторые из читателей, возможно, слышали термин «архитектура фон Неймана», часто употребляемый в контексте хвастовства: «а вот мы спроектировали уникальный не-фон неймановский компьютер». Естественно, ничего уникального в этом нет, хотя бы потому, что машины с фон неймановской архитектурой перестали строить еще в 1950-е годы.
После работы над ENIAC (который программировался в духе табуляторов, перетеканием огромного количества проводов, ни о каком управлении вычислениями с помощью программы, загруженной в память, и речи не шло) для следующей машины, названной EDSAC, Мочли и Эккерт продумали основные идеи ее конструкции.
Они таковы: однородная память, в которой хранятся команды, адреса и данные, они различаются между собой лишь по тому, как к ним обращаться и какой эффект они вызывают; память разделена на адресуемые ячейки, для обращения нужно вычислить двоичный адрес; и наконец, принцип программного управления – работа машины, представляет собой последовательность операций загрузки из памяти содержимого ячеек, манипуляцию над ними и выгрузку обратно в память, под управлением команд, последовательно же подгружаемых из той же памяти.
Почти все машины (а их было-то всего несколько десятков), произведенные в мире с 1945 по 1955 год, подчинялись этим принципам, так как строились академическими учеными, широко ознакомившимися с работой First Draft of a Report on the EDVAC, разосланной по вузам куратором фон Неймана Германом Голдстайном (Herman Heine Goldstine) от его имени.
Естественно, долго так продолжаться не могло, потому что чистая машина фон Неймана была, скорее, математической абстракцией, типа машины Тьюринга. Использовать ее для научных целей было полезно, реальные компьютеры же, построенные в соответствии с данными идеями, получались слишком тормозными.
Эпоха чистых машин фон Неймана кончилась еще в 1955–1956 годы, когда люди впервые стали задумываться о конвейерах, спекулятивном исполнении, data driven архитектуре и других подобных трюках.
В год смерти фон Неймана в Лос-Аламосской научной лаборатории был запущен компьютер MANIAC II (Mathematical Analyzer Numerical Integrator and Automatic Computer Model II) на 5 190 лампах, 3 050 диодах и 1 160 транзисторах.
Он работал с 48-битными данными и 24-битными инструкциями, имел ОЗУ на 4 096 слов и среднюю скорость 5 KIPS.
Машину конструировал Мартин Грехэм (Martin H. Graham), предложивший принципиально новую идею – помечать данные в памяти соответствующими метками-тегами для большей надежности и удобства программирования.
В следующем году Грехэма пригласили сотрудники Университета Райса в Хьюстоне, Техас, чтобы он помог им собрать компьютер, такой же мощный, как Лос-Аламосский. Проект R1 Rice Institute Computer продолжался три года, и в 1961 машина была готова (позже ее заменил стандартный для серьезных американских вузов IBM 7040, а его, что иронично, Burroughs B5500).
Схема декодирования 2-х инструкций на слово, как в MANIAC II, показалась Грехэму слишком навороченной, поэтому R1 оперировал 54-битными словами с инструкциями фиксированной ширины на все слово и имел похожую теговую архитектуру. Фактическая длина слова была равна 63 битам, из которых 7 – были кодом коррекции ошибок, а 2 – тегом.
Механизм косвенной адресации R1 был намного более продвинутым, чем в IBM 709 – фактически это были почти готовые дескрипторы из будущих машин Burroughs. Грехэм был также талантливым электротехником и изобрел для R1 новый тип лампово-диодной ячейки, названный Single Sided Gate и позволивший добиться отличной для тех лет частоты 1 МГц. Машина имела 15-битные адреса, 8 регистров данных/команд и 8 адресных регистров.

Первое поколение теговых архитектур появилось буквально сразу после смерти фон Неймана. Машины Айлифа и Грехэма, слева часть процессора MANIAC II, справа – сам Айлиф участвует в монтаже основной стойки R1. Фото https://www.sciencephoto.com и https://scholarship.rice.edu
Университет Райса для США – это что-то типа советского МИНХиГП, поэтому неудивительно, что создание компьютера (который собирались применять для исследования гидродинамики нефти) частично профинансировала Shell Oil Company.
Куратором с ее стороны выступил Боб Бартон (Robert Stanley Barton), талантливый инженер-электронщик. В 1958 году он прослушал курс математической логики и польской нотации в применении к алгебре и перешел на работу в Burroughs, в 1961 году построив им легендарный B5000, основанный на стековой теговой архитектуре.
Над программным обеспечением R1 трудился тот самый британец Айлиф. Его команда создала операционную систему SPIREL, символьный ассемблер AP1 и язык GENIE, ставший одним из предтеч ООП. ОС имела невероятно продвинутый по тем временам механизм динамического выделения памяти и сборщик мусора, а также механизмы защиты данных и кода.
Для своей операционной системы Айлиф разработал новый механизм адресации массивов с помощью вектора указателей на векторы данных. Эта идея была настолько прогрессивной по сравнению с адресацией в стиле Fortran (адрес содержит шаг и смешение для каждого элемента массива), что получила имя в честь создателя, и с тех пор векторы Айлифа использовались повсеместно, от Ferranti Atlas до Java, Python, Ruby, Visual Basic .NET, Perl, PHP, jаvascript, Objective-C и Swift.
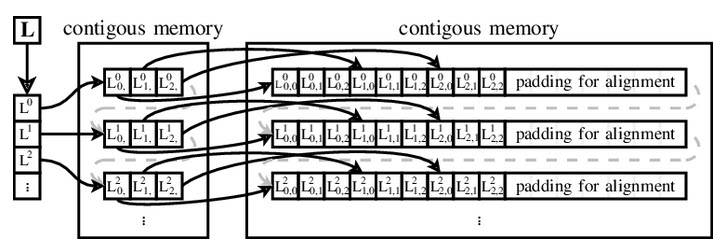
Использование вектора Айлифа для адресации матрицы 3х3 (https://www.researchgate.net)
В конце 1950-х годов теоретическая модель машины фон Неймана столкнулась с вызовом, на который не имела адекватного ответа (и потому умерла окончательно).
ЭВМ стали достаточно быстрыми, чтобы их не мог загрузить работой только один человек – появилась концепция классического мейнфрейма с терминальным доступом и многозадачной операционной системой.
Не будем углубляться в сложности, подстерегающие архитекторов на пути к многозадачности (для этого подойдет любой толковый учебник по проектированию операционных систем), отметим лишь, что для ее реализации критична реентерабельность кода, то есть возможность запустить несколько экземпляров одной и той же программы одновременно, работающих над разными данными, да так, чтобы данные одного пользователя были защищены от изменений другим пользователем.
Переложить все эти проблемы целиком на головы архитектора ОС и системных программистов казалось не совсем удачной идеей – слишком бы возросла сложность разработки ПО (вспомните, каким феерическим провалом закончился проект OS/360, Multics тоже не взлетела).
Существовал и альтернативный выход – создать подходящую архитектуру самого компьютера.
Именно эти возможности и рассмотрели практически одновременно коллеги по R1 – практик Бартон, сконструировавший B5000, и теоретик Айлиф, написавший те самые Basic Machine Principles, так вдохновившие Бурцева.
ICL (с которой мы так и не объединились) вела разработки продвинутых архитектур с 1963 по 1968 год (именно по итогам работы и была написана статья), Айлиф построил для них прототип BLM с аппаратными методами управления памятью, еще более продвинутыми, чем в машинах Burroughs.
Основной идеей Айлифа была попытка избежать стандартного для прочих систем (и в те годы медленного и неэффективного) механизма разделения памяти, основанного чисто на программных методах – переключении контекста (термин архитектуры ОС, означающий, по-простому, временную выгрузку и сохранение одного выполняющегося процесса и загрузку и начало выполнения другого) самой операционной системой. С его точки зрения аппаратный подход с использованием дескрипторов был намного эффективнее.
Проект BLM был закрыт в 1969 году, но его наработки частично использовались в продвинутой линейке мейнфреймов ICL 2900 Series, выпущенных в 1974 году (которые мы вполне бы могли разрабатывать совместно, но, увы).
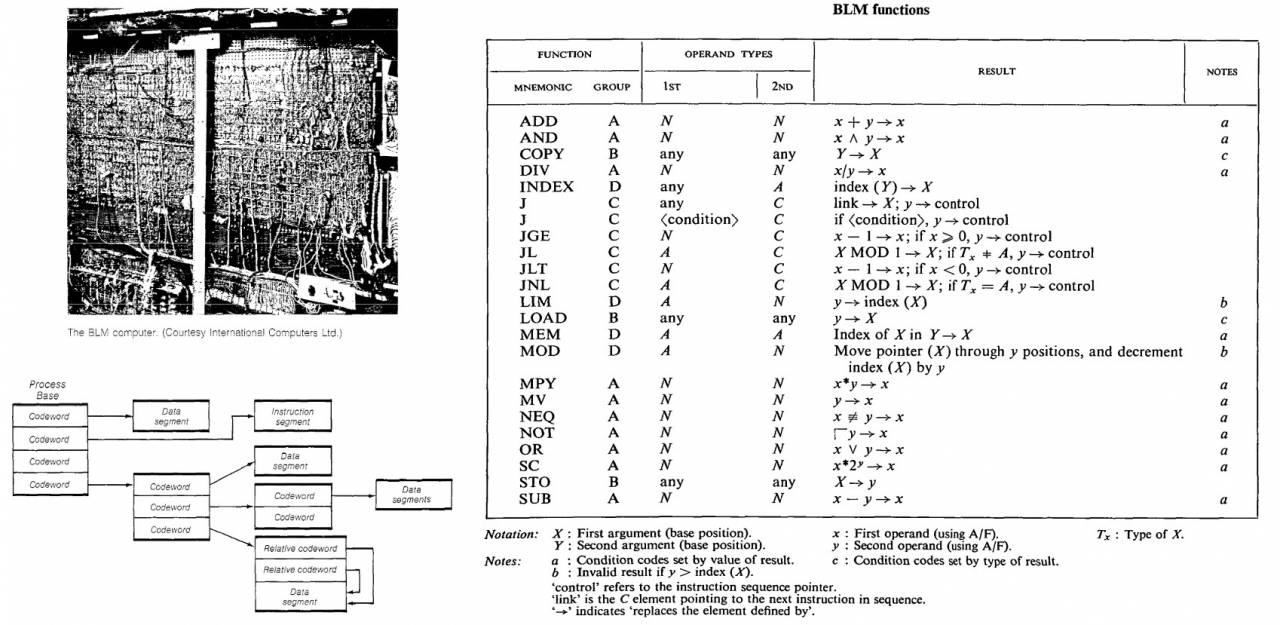
Второе поколение уже тегово-дескрипторных машин, от BLM осталась, к сожалению, только эта фотография из книги Descriptor-Based Computer Systems (Levy, Henry M. 1984). Система команд воспроизведена из оригинальной статьи Айлифа (чтобы читатели смогли погрузиться в проблему по следам Бурцева).
Естественно, проблема эффективной защиты памяти (а значит и разделения времени) волновала в 1960-е годы практически всех компьютерных ученых и корпорации.
Манчестерский Университет не остался в стороне и построил свой пятый компьютер, названный M.U.5.
Машина разрабатывалась в сотрудничестве с той же ICL с 1966 года, компьютер должен был в 20 раз превзойти по производительности Ferranti Atlas. Разработка продолжалась с 1969 по 1974 год.
M.U.5 управлялся операционной системой MUSS и включал три процессора – сам M.U.5, ICL 1905E и PDP-11. В наличии были все максимально продвинутые элементы: тегово-дескрипторная архитектура, ассоциативная память, предвыборка инструкций, в общем – это была вершина технологий тех лет.
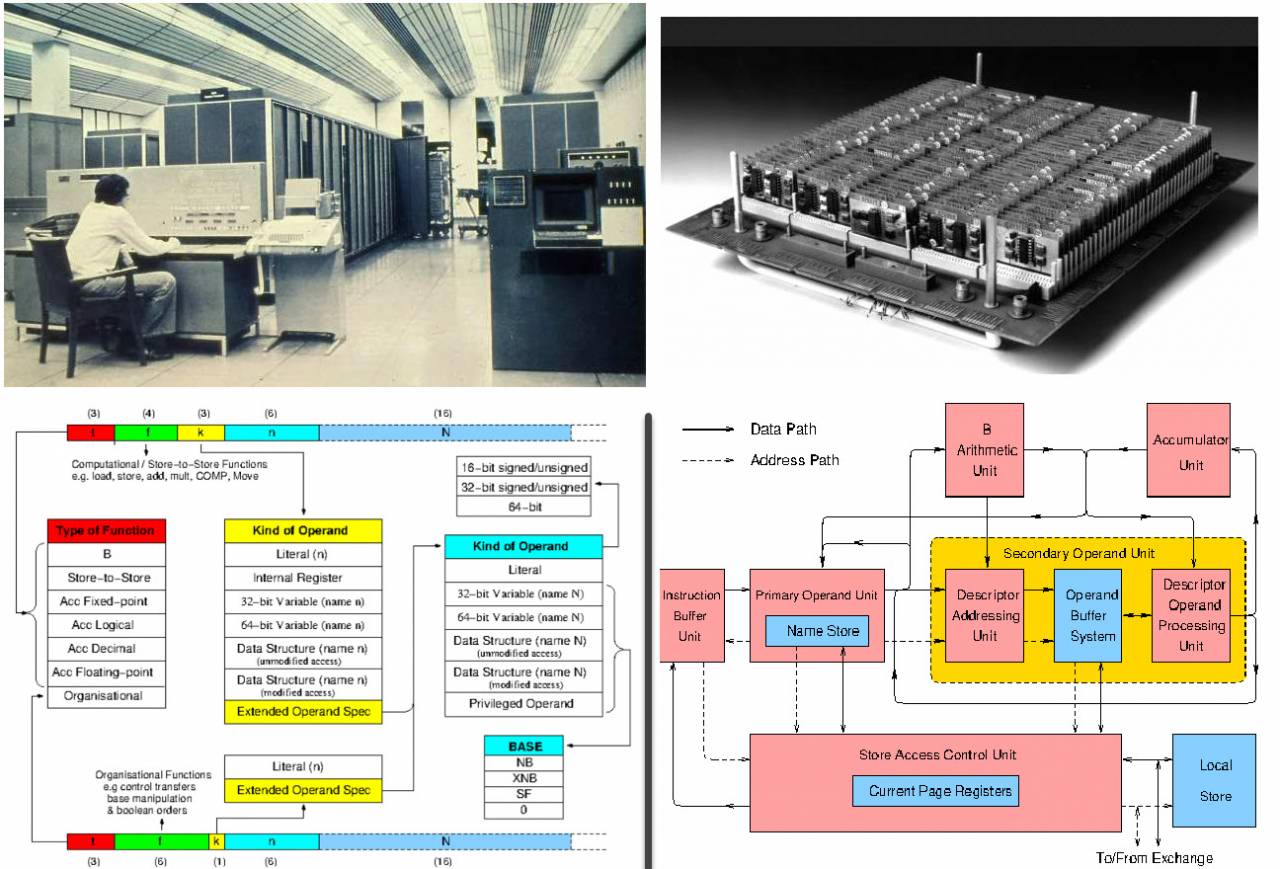
Манчестерская машина 5 – единственное фото, отличное описание системы команд и архитектуры (https://ethw.org)
M.U.5 послужил основой для ICL 2900 Series и отработал в университете до 1982 года.
Последним манчестерским компьютером стал M.U.6, состоящий из трех машин: M.U.66P – продвинутая микропроцессорная реализация, используемая как ПК; M.U.66G – мощный скалярный научный суперкомпьютер и M.U.66V – векторно-параллельная система.
Разработать микропроцессорную архитектуру ученые уже не осилили, M.U.66G был создан и отработал на кафедре с 1982 по 1987 годы, а для M.U.66V был построен прототип на Motorola 68k с эмуляцией векторных операций.

ICL 2900 Series стали одними из немногих оригинальных машин, которые довольно бодро конкурировали с S/360. Для британских пользователей 1980-х эта серия полна тепла и ностальгии, как для советских БЭСМ-6. Фото http://www.tavi.co.uk и http://www.computinghistory.org.uk
Дальнейшим прогрессом дескрипторных машин должна была стать схема т. н. capability-based addressing (буквально «адресации на основе возможностей», не имеет устоявшегося перевода на русский, так как с такими машинами отечественная школа была незнакома, в переводе книги «Архитектура современных ЭВМ: в 2-х книгах» (Майерс Г. Дж.,1985 г.) она очень удачно названа потенциальной адресацией).
Смысл потенциальной адресации заключается в том, что указатели заменяются специальными защищенными объектами, которые могут быть созданы только с помощью привилегированных инструкций, выполняемых лишь особым привилегированным процессом ядра ОС. Это позволяет ядру контролировать, какие процессы могут обращаться к каким объектам в памяти, вообще без необходимости использовать отдельные адресные пространства и, следовательно, не имея накладных расходов на переключение контекста.
В качестве косвенного эффекта такая схема приводит к однородной или плоской модели памяти – отныне (с точки зрения даже низкоуровневого программиста драйверов!) нет интерфейсного различия между объектом в ОЗУ или на диске, обращение происходит абсолютно единообразно, с помощью вызова защищенного объекта. Список объектов может храниться в специальном сегменте памяти (как, например, в Plessey System 250, созданной в 1969–1972 годах и представляющей собой воплощение в железе весьма эзотерической вычислительной модели, называемой λ-исчисление) или кодироваться специальным битом, как в прототипе IBM System/38.
Plessey System 250 разрабатывался для военных, и в качестве центральной машины коммуникационной сети Министерства обороны успешно использовался во время войны в Персидском заливе.
Этот компьютер представлял собой абсолютную вершину сетевой безопасности, машина, в которой не существует суперпользователей с неограниченными полномочиями как класса и не имеется способа повысить свои привилегии через взлом для исполнения того, что не должно быть исполнено.
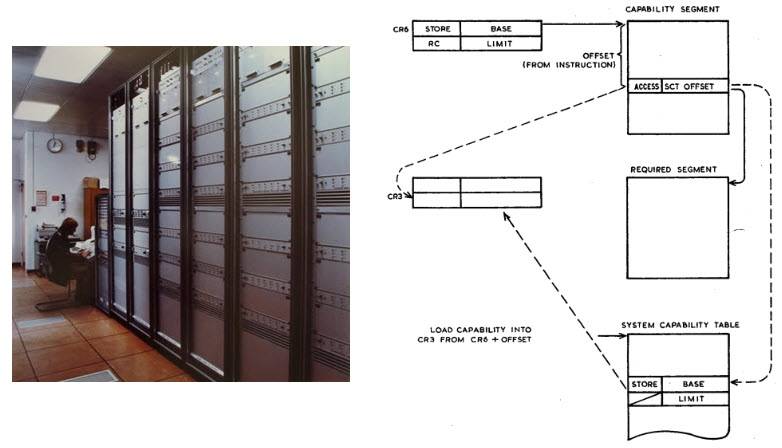
Plessly 250 единственное известное фото (из коллекции Kenneth J Hamer-Hodges) и схема работы потенциальной адресации из монографии Capability Concept Mechanisms And Structure In System 250, D. M. England, 1974.
Подобная архитектура считалась невероятно прогрессивной и передовой в 1970–1980 годы и разрабатывалась многими фирмами и исследовательскими группами, известны машины CAP computer (Кембридж, 1970–1977 гг.), Flex Computer System (Royal Signals and Radar Establishment, 1970-е), Three Rivers PERQ (Carnegie Mellon University и ICL, 1980–1985 гг.) и самый знаменитый проект – провальный микропроцессор Intel iAPX 432 (1981 г.).
Забавно, что инициаторами 90 % всех максимально оригинальных и странных архитектурных решений в 1960–1970-е годы были англичане (в 1980-е – японцы, с аналогичным результатом), а не американцы.
Британские ученые (да-да, те самые!) изо всех сил старались удержаться на гребне волны и подтвердить свою квалификацию выдающихся теоретиков computer science. Жаль только, что, как и в случае с советской академической разработкой компьютеров, все эти проекты были феноменальны только на бумаге.
ICL отчаянно пыталась войти в мировой топ производителей передового железа, но, увы, дело не пошло.
Американцы вначале подумали, что англосаксонские коллеги, учитывая их пионерский вклад в ИТ со времен Тьюринга, плохого не посоветуют, и дважды жестоко обожглись – и Intel iAPX 432 и IBM System/38 с треском провалились, что вызвало великий поворот середины 1980-х в сторону современных архитектур процессоров (как раз тогда американская школа компьютеростроения открыла принцип RISC-машин, оказавшийся до того удачным со всех сторон, что 99 % современных компьютеров так или иначе строятся по этим лекалам).

CAP computer до сих пор стоит в лаборатории Кембриджа, прототип IBM System/38 и рабочая станция Three Rivers PERQ (фото https://en.wikipedia.org и https://www.chiark.greenend.org.uk)
Иногда даже интересно – какие разработки выкатила бы полноценно объединенная советско-британская школа годам так к 1980-м с их передовой культурой производства, нашими общими безумными идеями и возможностью СССР вливать миллиарды нефтедолларов в развитие?
Очень жаль, что эти возможности закрылись навсегда.
Естественно, информация обо всех передовых разработках британцев попадала к Бурцеву буквально из первых рук и день в день, с учетом, что ИТМиВТ имел отличные контакты и с Манчестерским университетом (еще с начала 1960-х годов и работы над БЭСМ-6), и с фирмой ICL, с которой Лебедев так хотел заключить союз. Однако единственной коммерческой реализацией тегово-дескрипторных машин был все-таки Burroughs.
Что можно сказать о работе Бурцева с этой машиной?
Невероятные приключения Burroughs в России
Советский компьютинг являлся чрезвычайно закрытой областью, по многим машинам не существует фотографий, толковых описаний (про архитектуру Китовской М-100, например, толком ничего неизвестно до сих пор), да и вообще сюрпризы поджидают на каждом шагу (как открытие в 2010-х годах ЭВМ «Волга», о существовании которой не подозревали даже Ревич, Малиновский и Малашевич, бравшие десятки интервью и писавшие на их основе книги).
Но в одной особой области умолчаний и секретов было больше, чем даже в военных машинах. Это упоминания об американских компьютерах, работавших в Союзе.
Эту тему настолько не любили поднимать, что может сложиться впечатление, что, кроме общеизвестного CDC 6500 в Дубне, американских ЭВМ в СССР вообще не было как класса.
Даже информацию о CYBER 170 и 172 пришлось добывать по крупицам (а ведь были и HP 3000, стоявшие в АН СССР и куча других!), наличие же в Союзе настоящего живого Burroughs и вовсе многие считали мифом.
Ни в одном русскоязычном источнике, интервью, форуме, книге – нигде нет даже строки, посвященной судьбе этих машин в СССР. Однако, как всегда, наши западные друзья знают о нас куда больше, чем мы сами.
В результате тщательных поисков было установлено – Burroughs в Соцблоке нежно любили и вовсю использовали, хотя отечественные источники тут как воды в рот набрали.
К счастью, в США достаточно поклонников этой архитектуры, которые знают о ней все, в том числе – полное количество инсталляций каждой модели их мейнфреймов, вплоть до серийных номеров. Они обобщили эту информацию в таблицу, которой щедро поделились, документ включает также источники информации о каждой поставке компьютеров Burroughs в страны Варшавского договора.
Итак, обратимся к книге Economic Statecraft during the Cold War: Eurpoean Responses to the US Trade embargo, которая раскрывает нам тайны советских закупок.
Early in October 1969 an administration interagency staff study group… By this time US computer corporations commenced selling in East Europe. The Burroughs Corporation of Detroit installed four of their large B5500 computers in Czechoslovakia and one in Moscow that were equal to the mid-range of IBM's computers. Soviet programmers and maintenance staff were trained at the Detroit Plant.
О как, к 1969 году Burroughs B5500 был не только установлен в Москве, но и советские специалисты успели пройти стажировку на фабрике компании в Детройте!
Еще 4 машины были проданы в Чехословакию по правительственному заказу, к сожалению, неизвестно, где они были установлены и чем занимались, но явно не в университетах, в графе «пользователь» в таблице указано «government». Мощнейший B6700 (позже апгрейд до B7700!) был продан в ГДР и использовался в University of Karlsruhe.
Дальнейшие попытки уточнить информацию о поставках в Москву заставили нас связаться с Southwest Museum of Engineering, Communications and Computation (Аризона, США).
На их сайте можно найти примечание к статье Алистера Майера из журнала ACM's Computer Architecture News за 1982 год (Alastair J.W. Mayer, The Architecture of the Burroughs B5000 – 20 Years Later and Still Ahead of the Times), это письмо инженера Ри Вильямса (Rea Williams) из группы инсталляции и техподдержки Burroughs Corporation:
Well way back when, I do not remember the exact year, around 1973 … Burroughs sold a B6500 (B6700) to the Oil Ministry of Russia. It was a very special system with Cyrillic printers, special paper tape readers and some other very special stuff. This was during the cold war, but we (Burroughs) had some special permission to supply the system. I participated in the system «ride out» at the City of Industry plant. Glen was with our TIO organization and went to Russia to help install and train the local people to maintain it. He told stories of the GRU or whatever distrusting their card games because they thought the Burroughs guys were «collaborating» or something and they had to leave their room doors open. Great stories, wish I could remember them all. So, at the end he gave me the pin. I have some other stuff around that I will tell you about as well, later.
Кстати, Советы в честь такого события выпустили памятные значки с эмблемой Burroughs и надписью «Барроус» и раздали их участникам проекта. Оригинал значка, принадлежащий Вильямсу, украшает заголовок этой статьи.
Итак, советская нефтяная промышленность (вообще параллельная всему беспределу, который творился у нас вокруг военных и научных компьютеров), будучи чрезвычайно влиятельной, богатой и бесконечно далекой от всех разборок Академии и партии, не желая довольствоваться отечественными ЭВМ (и абсолютно не желая что-то там у кого-то из советских НИИ заказывать и ждать, когда через десять лет разборок они все провалят), спокойненько так взяла и сама себе купила лучшее, что могла – отличный B6700. Они даже вызвали группу инсталляции из самой корпорации, чтобы драгоценная машина работала как надо.
Неудивительно, что об этом эпизоде, ясно показывающем, как действительно серьезные люди (не будем забывать, что нефтяники и приносили стране большую часть денег, которую потом спускали на свои игрища военные и академики) относились к отечественным машинам, постарались забыть покрепче.

Burroughs B6700 Университета Тасмании и последний в линейке Burroughs Large Systems – великий B7900 (http://www.retrocomputingtasmania.com, https://pretty-little-fools.tumblr.com)
Отметим два интересных факта.
Во-первых, несмотря на то, что Burroughs все знают в основном по поставкам их мейнфреймов (как золотого эталона защищенной архитектуры) для Федеральной резервной системы США, они имели и военные заказы (хотя и куда меньше, чем IBM и Sperry, сказалось то, что в годы Второй мировой войны у них не вышло наладить контакты с правительством).
А кроме того, их машины очень-очень любили университеты. Можно сказать даже – обожали, по всему миру: в Британии, Франции, Германии, Японии, Канаде, Австралии, Финляндии и даже Новой Зеландии было установлено более сотни мейнфреймов Burroughs разных линеек. Архитектурно (и с точки зрения стиля) Burroughs был своеобразным Apple в мире больших компьютеров.
Их машины были защищенными и феноменально надежными, дорогими, мощными, поставлялись абсолютным комплектом со всем предустановленным и настроенным ПО и пакетами программ, архитектура была закрытой, отличаясь от всего на рынке.
Их любили интеллектуалы всех мастей за то, что Burroughs (прямо как Macintosh золотой эры) просто включаешь и работаешь. По меркам мейнфреймов тех лет, даже таких удачных, как S/360, это было невероятно круто.
Ну и, конечно, они отличались дизайном, фирменными удобными терминалами, оригинальной системой загрузки дисков и многими другими вещами. Отметим и то, что в свои годы это был хоть и не суперкомпьютер, но мощная рабочая машина, выдававшая около 2 MFLOPS – мощнее всего, что было у СССР в тот момент, в несколько раз.
В общем, университеты их заслуженно любили, так что использование Burroughs в качестве научного суперкомпьютера в Союзе было бы вполне оправданным решением. Отдельным бонусом шла аппаратная поддержка Algol – языка, считавшегося, во-первых, золотым вузовским стандартом (особенно в Европе), во-вторых, чрезвычайно тормознутом на любых других архитектурах.
Algol (полной поддержки которого так и не появилось в чисто отечественных машинах) заслуженно считался эталоном классического академического структурного программирования. Не перегруженный эзотерическими конструкциями, как PL/I, не такой анархический, как Pure C, в разы удобнее, чем Fortran, куда менее мозголомающий, нежели LISP и (боже упаси) Prolog.
До появления концепции ООП ничего совершеннее и удобнее создано не было, и Burroughs были единственными машинами, на которых он не тормозил.
Еще один факт заслуживает большого внимания.
КоКом категорически не позволял нам закупать продвинутые архитектуры, даже ограничения на мощные рабочие станции 1980-х были сняты только после развала СССР, за CDC пришлось люто биться, CYBER продавали со скрипом (как мы уже упоминали, директор Control Data аж попал под расследование Конгресса об антиамериканской деятельности), причем несколько машин были установлены с целями, отвечающими интересам США.
CYBER из Гидрометцентра нам отдали за помощь с данными по арктическому климату, а CYBER ЛИАН – в обмен на обещание совместной разработки рекурсивных ЭВМ.
В итоге, кстати, зря продали, совместной работы не вышло.
Реального автора идеи, Торгашова, быстренько задвинули куда подальше его начальники, как только на горизонте замаячила слава и деньги от работы с янки. Американцы приехали, попытались добиться каких-то телодвижений в разработке от начальников, с трудом представляющих, как обычные-то машины работают, плюнули в итоге на все и уехали.
Так СССР потерял еще одну возможность войти на мировой рынок.
А вот свежие Burroughs нам поставляют, не моргнув и глазом, ни КоКом ни Конгресс не возражают, никаких претензий. Оправдать это можно лишь, опять-таки, интересами большого бизнеса.
Продавали его нефтяникам с гарантией, что военным они свою прелесть явно не отдадут, самим нужен, а вот дружить с советской нефтянкой очень выгодно обеим сторонам.
Отметим и то, что начали нам продавать Burroughs как раз в годы Брежнева, когда накал холодной войны значительно снизился, как мы и писали в предыдущих статьях. При этом хитрые янки не спешили накачивать своих противников чисто военными технологиями (типа мощнейшего CDC 6600 или Cray-1), но поддержать советский бизнес они не возражали.
В диссертации на соискание степени PhD in Business Administration Петера Волкотта (Peter Wolcott) из Университета Аризоны Soviet Advanced Technology: The Case of High-Performance Computing, опубликованной еще в 1993 году, впрочем, утверждается, что B6700 был инсталлирован в Москве в 1977 году (то есть на все согласования и доставку суммарно ушло 4 года!).
Большая часть эскизных проектных работ по «Эльбрусу» была завершена с 1970 по 1973 год, когда живую машину Бурцев мог видеть только в США (к сожалению, нет информации, когда точно он туда ездил).
В это время инженеры ИТМиВТ имели доступ только к общей документации по B6700 – архитектуре команд и блок-схемам машины. Волкотт пишет, что более подробную информацию они получили в 1975–1976 годы (видимо, после поездки Бурцева, привезшего кучу бумаг), что привело к некоторым доработкам и изменениям в структуре «Эльбруса».
Наконец, в 1977 разработчики детально изучили московский Burroughs, что привело к еще одной волне апгрейда, вероятно, с этим в т. ч. и связан непрерывный процесс внесения изменений в уже поступающие на производство документы.
В силу этого мы можем гарантировать, что вдохновение посетило Бурцева явно под воздействием, прежде всего, работ британцев, с которыми он мог ознакомиться еще в середине 1960-х годов. И да, в те времена направление тегово-дескрипторных машин действительно считалось «в теоретическом плане наиболее сильным», то есть поддерживалось, как наиперспективнейшее, практически всей академической компьютерной наукой Британии.
В этом отношении работа над «Эльбрусом» находилась в русле самых передовых на тот момент исследований, и не вина британских академиков, что в середине 1980-х мир повернул совсем в ином направлении.
Отметим и то, что по теоретическим статьям построить машину у коллектива Бурцева не вышло, только ознакомление с документацией на живой Burroughs позволило им до конца разобраться, как работает эта штука.
Сравнение архитектур
Вся линейка Burroughs Large Systems Group строилась на единственной архитектуре B5000. Обозначения машин были крайне экстравагантными. Последние три цифры обозначали поколение машин, а первая – порядковый номер по мощности в поколении.
Таким образом, у нас имелась в наличии серия 000 (единственный представитель – родоначальник B5000), затем числа со 100 по 400 не использовались (они пошли на Medium Systems и Small Systems), и следующая серия получила индекс 500. В ней было три компьютера, разделенных по мощности – попроще (B5500), посложнее (B6500) и в теории самый мощный (B8500).
Однако уже B6500 забуксовал, и в итоге серия застряла на младшей модели. Следующее число 600 тоже выпало (чтобы не путали с фирмой CDC), и так появилась линейка B5700, B6700 и B7700.
Различались они объемом памяти, числом процессоров и прочими архитектурно не принципиальными деталями. Наконец, последней линейкой стала 800-я серия из двух моделей (B6800 и B7800) и 900-я из трех (B5900, B6900 и B7900).
Весь код, написанный для Large Systems, является реентерабельным, что называется – из коробки, и никаких дополнительных усилий для этого системный программист прилагать не должен. Если говорить элементарно – программист просто писал код, вообще не думая о том, что он может работать в многопользовательском режиме, управление им система брала на себя.
Ассемблер отсутствовал, системным языком являлось надмножество ALGOL – язык ESPOL (Executive Systems Problem Oriented Language), на котором было написано ядро ОС (MCP, Master Control Program) и все системное ПО.
В 700-й серии он был заменен более продвинутым языком NEWP (New Executive Programming Language). Для эффективной работы с данными были разработаны еще два расширения – DCALGOL (data comms ALGOL) и DMALGOL (Data Management ALGOL), а для эффективного управления MCP появился отдельный язык командной строки WFL (Work Flow Language).
Компиляторы Burroughs COBOL и Burroughs FORTRAN были также написаны на ALGOL и тщательно оптимизированы для учета всех нюансов архитектуры, поэтому версии этих языков для Large Systems являлись лучшими по быстродействию на рынке.
Разрядность больших машин Burroughs условно составляла 48 бит (+3 бита тега). Программы состояли из особых сущностей – 8-битных слогов, которые могли быть вызовом имени, значения или же составлять оператор, длина которого варьировалась от 1 до 12 слогов (это было существенным новшеством 500 серии, классический B5000 использовал фиксированные инструкции длины 12 бит).
Сам язык ESPOL насчитывал менее 200 операторов, все они помещались в 8-битные слоги (включая мощные операторы редактирования строк и подобные, без них насчитывалось всего 120 инструкций). Если убрать операторы, зарезервированные для операционной системы, такие как MVST и HALT, то набор обычно используемых программистами пользовательского уровня составит менее 100. Некоторые операторы (такие как Name Call и Value Call) могли содержать явные адресные пары, прочие использовали продвинутый стек с ветвлением.
Burroughs не имел регистров, доступных программисту (для машины как пара регистров интерпретировалась вершина стека и следующая за ней), соответственно, не было необходимости в операторах для работы с ними, равно были не нужны и разнообразные суффиксы/префиксы для указания вариантов выполнения операций между регистрами, поскольку все операции применялись к вершине стека. Это делало код чрезвычайно плотным и компактным. Многие операторы являлись полиморфными и меняли свою работу в соответствии с типами данных, которые определяли тегами.
Например, в наборе инструкций Large Systems есть только один оператор ADD. Типичный современный ассемблер содержит несколько операторов сложения для каждого типа данных, например add.i, add.f, add.d, add.l для целочисленных, плавающих, с двойной точностью и длинных чисел. В Burroughs архитектура различает только числа одинарной и двойной точности – целые являются просто вещественными с нулевой экспонентой. Если один или оба операнда имеют тег 2, выполняется сложение с двойной точностью, в противном случае тег 0 указывает на одинарную точность. Это означает, что код и данные никогда не могут быть несовместимы.
Работа со стеком в Burroughs реализована очень красиво, не будем утомлять читателей деталями, просто поверьте на слово.
Отметим лишь то, что арифметические операции занимали один слог, операции работы со стеком (NAMC и VALC) – два, статические ветвления (BRUN, BRFL и BRTR) – три, а длинные литералы (например, LT48) – пять. В результате код был намного плотнее (точнее – имел большую энтропию), чем в современной архитектуре RISC. Увеличение плотности понижало промахи кэша инструкций и, следовательно, улучшало производительность.
Из системной архитектуры отметим SMP – симметричную мультипроцессорность до 4 процессоров (это в 500 серии, начиная с 800-й серии SMP сменилось NUMA – Non-uniform memory access).
Burroughs вообще были пионерами в использовании нескольких процессоров, соединенных высокоскоростной шиной. Линейка B7000 могла иметь до восьми процессоров, при условии, что хотя бы один из них был модулем ввода/вывода. B8500 должен был иметь 16, но был в итоге отменен.
В отличие от Сеймура Крэя (и Лебедева с Мельниковым), инженеры Burroughs развивали идеи массивно-параллельной архитектуры – соединения множества относительно слабых параллельных процессоров с общей памятью, а не использования одного сверхмощного векторного.
Как показала история – это подход в итоге оказался самым лучшим.
Кроме того, Large Systems стали первыми стековыми машинами на рынке, их идеи позже легли в основу языка Forth и компьютеров HP 3000. Burroughs был первопроходцем использования т. н. стека сагуаро (это такой кактус, так называют стек с ветвлениями). В стеке хранились все данные, за исключением массивов (которые могли включать как строки, так и объекты), для них выделялись страницы в виртуальной памяти (первая коммерческая реализация этой технологии, опередившая S/360).
Еще одним широко известным аспектом архитектуры Large Systems являлось использование тегов. Эта концепция изначально появилась в B5000 в целях повышения безопасности (там тег просто разделял код и данные, наподобие современного бита NX), начиная с 500-й серии роль тегов была значительно расширена. Под них отвели 3 бита вместо 1, таким образом, всего было доступно 8 вариантов тегов. Вот некоторые из них: SCW (Software Control Word), RCW (Return Control Word), PCW (Program Control Word) и так далее. Красота идеи заключалась в том, что бит 48 был доступен только для чтения, поэтому нечетные теги обозначали управляющие слова, которые не могли быть изменены пользователем.
Стек – это очень хорошо, но как работать с объектами, которые в него не влезают из-за своей структуры, например, строками? Нам ведь потребуется аппаратная поддержка работы с массивами.
Очень просто, Large Systems использует для этого дескрипторы. Дескрипторы, как явствует из названия, описывают области хранения структур, а также запросы и результаты I/O. Каждый дескриптор содержит поле, указывающее его тип, адрес, длину и наличие данных в хранилище. Естественно, они помечаются своим тегом. Архитектура дескрипторов Burroughs также очень интересна, но мы не будем здесь углубляться в детали, отметим только, что через них реализовывалась виртуальная память.
Разница между Burroughs и большинством других архитектур заключается в том, что в них используется страничная виртуальная память, то есть страницы выгружаются в виде кусков фиксированного размера, независимо от структуры информации в них. Виртуальная память B5000 работает с сегментами разного размера, которые описываются дескрипторами.
В ALGOL границы массива полностью динамические (в этом смысле Pascal со своими статичными массивами куда примитивнее, хотя в версии Burroughs Pascal это исправлено!), и в Large Systems массив выделяется не руками при его объявлении, а автоматически при обращении к нему.
В результате становятся ненужными низкоуровневые системные вызовы выделения памяти, такие как легендарный malloc в C. Это убирает огромный пласт всевозможных выстрелов себе в ногу, которыми так славен C, и избавляет системного программиста от кучи сложной и муторной рутины. Фактически Large Systems – это машины, поддерживающие сборку мусора а-ля JAVA, причем аппаратно!
Что забавно, многие пользователи Burroughs, перешедшие на него в 1970–1980 годы и портировавшие свои (вроде бы корректно работающие!) программы с языка С, обнаружили в них массу ошибок, связанных с выходом за пределы буфера.
Проблема физических ограничений на длину дескриптора, не позволяющих адресовать более 1 Мб памяти напрямую, была изящно решена в конце 1970-х с появлением механизма ASD (Advanced Segment Descriptors), позволяющего выделять уже терабайты ОЗУ (в персональных компьютерах такое появилось только в середине 2000-х).
Кроме этого, т. н. p-bit прерывания, означающий, что выделен блок виртуальной памяти, в Burroughs можно использовать для анализа производительности. Например, так можно обратить внимание, что процедура, выделяющая массив, постоянно вызывается. Обращение к виртуальной памяти резко снижает производительность, именно поэтому современные компьютеры начинают работать быстрее, если воткнуть еще одну плашку ОЗУ.
В машинах Burroughs анализ p-bit прерываний позволял найти системную проблему в софте и лучше сбалансировать нагрузку, что важно для мейнфреймов, работающих 24х7 весь год. В случае больших машин экономия даже пары минут времени в сутки оборачивалась неплохим итоговым приростом производительности.
Наконец, дескрипторы, как и теги, отвечали за значительное увеличение безопасности кода. Одним из лучших инструментов, которыми располагает хакер для компрометации современных ОС – это классическое переполнение буфера. Язык C, в частности, использует самый примитивный и чреватый ошибками способ маркировки конца строк, используя нулевой байт в качестве сигнализатора конца строки в самом потоке данных (вообще, такая неряшливость отличает многие вещи, созданные, можно сказать, в академическом стиле, то есть умными людьми, не имеющими, однако, специальной квалификации в области разработки).
В Burroughs указатели реализованы индексными дескрипторами. Во время индексирования они аппаратно проверяются при каждом инкременте/декременте, чтобы избежать выхода за границы блока. Во время любого чтения или копирования и исходный, и целевой блоки контролируются дескрипторами, защищенными от изменения, для того чтобы сохранять целостность данных.
В итоге значительный класс атак становится в принципе невозможным, и многие ошибки в ПО можно отловить еще на этапе компиляции.
Неудивительно, что Burroughs так полюбился в университетах. В 1960–1980-е годы квалифицированные программисты, как правило, работали в крупных корпорациях, ученые писали для себя софт сами, в итоге Large Systems колоссально облегчали их работу, лишая возможности фундаментально накосячить в какой-нибудь программе.
Burroughs повлиял на огромное количество технологий.
Как мы уже говорили, линейка HP 3000 и также их легендарные калькуляторы, используемые до сих пор, были вдохновлены стеком Large Systems. Отказоустойчивые серверы Tandem Computers тоже несли в себе отпечаток этого инженерного шедевра. Кроме Forth, идеи Burroughs значительно повлияли на Smalltalk – отца всего ООП и, конечно, на архитектуру виртуальной машины JAVA.
Почему же такие великие машины вымерли?
Ну, во-первых, они вымерли далеко не сразу, классическая самая настоящая тегово-дескрипторная архитектура Burroughs непрерывно продолжалась в линейке мейнфреймов UNISYS вплоть до 2010 годов и только тогда сдала позиции серверам на банальных Intel Xeon (конкурировать с которыми адски тяжело даже IBM). Вытеснение произошло по одной банальной причине, угробившей и все прочие экзотические машины 1980-х годов.
В 1990-е процессоры общего назначения, подобные DEC Alpha и Intel Pentium Pro прокачались до такой колоссальной производительности, что огромное количество изысканных архитектурных трюков стало просто ненужным. SPARCserver–1000E на паре 90 МГц SuperSPARC-II уделывал «Эльбрус» всех вариантов как бог черепаху.
Второй причиной заката Burroughs стали те же проблемы, что чуть не угробили Apple в 1980-е, усугубленные мейнфреймовыми масштабами бизнеса. Их машины были настолько сложны, что разработка обходилась чрезвычайно дорого и занимала много времени, поэтому, по сути, все 1970-е они изготавливали лишь чуть улучшенные версии одной и той же архитектуры. Как только Burroughs пытался двинуться куда-то еще (как в случае с B6500 или B8500) – проект начинал буксовать, поглощать деньги со скоростью черной дыры и в итоге отменялся (как провальные Apple III и Lisa).
Мейнфреймовые масштабы же означали, что Burroughs торговали компьютерами за миллионы долларов с безумно дорогим обслуживанием. Например, B8500 должен был иметь 16 процессоров, но расчётная стоимость конфигурации даже с тремя составляла более $14 млн, и поэтому контракт на его поставку был расторгнут.
Кроме феноменальной стоимости самих машин, старшие мейнфреймы компании требовали огромного количества денег на поддержку. Годовой пакет техобслуживания, сервиса и все лицензии на все ПО, в случае самой топовой модели B7800, стоил около $1 млн в год, далеко не все могли позволить себе такую роскошь!
Вот интересно, советские нефтяники покупали полный сервис или чинили свой Burroughs сами, крепким словом и кувалдой?
Поэтому бизнес Burroughs всегда шел прихрамывая, им очень не хватало масштабов и силы IBM. Делать дешевые машины они не могли в силу сложности разработки, а покупателей на дорогие машины, с учетом активной битвы с конкурентами, было недостаточно для повышения прибыли и возможности вложить лишние деньги в разработку и снизить цены, сделав машины более конкурентоспособными.
Компания Sperry UNIVAC страдала теми же проблемами, в итоге в 1986 году две корпорации, чтобы выжить, слились в UNISYS, производящую мейнфреймы до сих пор.
Кроме упомянутых архитектур, Бурцев действительно использовал опыт 5Э26 и 5Э92б в плане аппаратного контроля над ошибками. Оба этих компьютера были способны аппаратно детектировать и исправлять любые однобитные ошибки, а в проекте «Эльбрус» этот принцип был поднят на новую высоту.
Итак, нас ждет ответ на самый увлекательный вопрос – так был ли «Эльбрус» «Эль-Берроузом»?
Как мы помним, Айлиф отказался от классической модели фон Неймана, машины как линейного хранилища инструкций и данных. Стек сагуаро в Burroughs представлял собой древовидную структуру, отражающую выполнение параллельного кода и иерархию процессов в мультипользовательской мультипрограммной среде. Отметим, кстати, что ALGOL с его блочной иерархической структурой идеально ложится на стек, именно поэтому его реализация в Large Systems была столь удачна.
Эта философия интегрированного дизайна была нетривиально продвинута системными архитекторами «Эльбруса», поднявшими ее на новый уровень. В частности, вместо нескольких специализированных языков группа разработчиков из ИТМиВТ создала один универсальный, алголоподобный Эль-76.
На этом архитектурные новинки не закончились.
Прямое сравнение машин дано в таблице ниже, старичок B6700 в целом неплохо смотрится на фоне компьютера на 17 лет моложе.
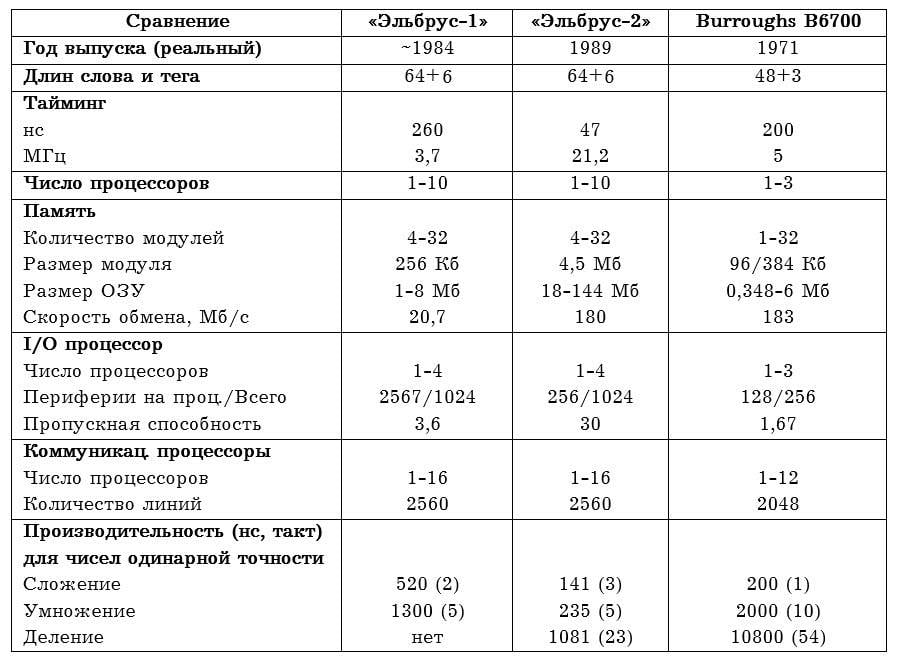
Из интересного – в отличие от B6700, «Эльбрус» был чудовищно огромным.
Первая версия занимала 300 кв. м в однопроцессорной и 1 270 кв. м в 10-процессорной конфигурации, а вторая – соответственно 420 и невероятные 2 260 кв. м, отбирая тем самым лавры самого большого компьютера в истории у самого IBM AN/FSQ-7 Project SAGE, который, будучи ламповым, занимал 1 860 кв. м.

Для осознания масштабов. Wembley Stadium. Примерно столько занимал многомашинный комплекс «Эльбрусов» для ПРО А-135.
Центральный процессор обеих машин основан на стековой CISC архитектуре с обратной польской нотацией. Код скомпилированной программы состоит из набора сегментов. Сегмент, как правило, соответствует одной процедуре или блоку в программе. Когда начинается выполнение программы, выделяется два участка памяти: один для стека, другой – для словаря сегментов, который используется для ссылок на множество сегментов программы в ОЗУ. Участки памяти для сегментов кода и массивов выделяются ОС по требованию.
Дескрипторы в обеих машинах отвечают за реентерабельность кода, организовывая автоматическое разделение памяти между исполняемыми потоками. Код и данные жестко разделены тегами, дескрипторы позволяют запускать идентичный код на различных наборах данных для разных пользователей, с гарантией их защиты.
Обе ЭВМ используют даже идентичные регистры специального назначения (например, в каждой машине есть регистры base-of-stack, stack limit и top-of-stack) и команды управления стеком.
Burroughs и «Эльбрус» имеют очень похожую философию, но сильно различаются по конструкции самого процессора.
Процессор B6700 состоит из 48-разрядного сумматора, блока обработки адресов, семи функциональных контроллеров (программный, арифметический, строковый, регулировки стека, прерывания, передачи и памяти) и набора регистров. Последние включают 4 51-битных регистра данных (два верхних элемента стека, текущее значение, промежуточное значение) и 48 20-битных регистров команд (32 дисплейных регистра, отвечающих за хранение точек входа в процедуры, исполняемые в настоящий момент, и по 8 регистров базовых адресов и индексных регистров).
Самым интересным в процессоре был чрезвычайно хитрый блок т. н. контроллеров семейства операций (в количестве 10 штук), которые из имеющихся функциональных блоков выстраивали для каждой команды вычислительный конвейер. Это позволило значительно сократить затраты транзисторов.
Устройство управления передает декодированную инструкцию в регистр Current Program Instruction Word и выбирает соответствующий контроллер семейства операторов. Ключевой особенностью является то, что инструкции выполняются строго последовательно в порядке, продиктованном компилятором. Арифметические инструкции не могут выполняться с перекрытием, так как в ЦП имеется только один сумматор.
Это и было основным отличием процессора «Эльбрус». Бабаян гордо бил себя кулаком в грудь и заявлял о «первом в мире суперскаляре в Эльбрусе» (к разработке которого он не имел ни малейшего отношения вообще), но на практике Бурцев тщательно изучил архитектуру великого CDC 6600, чтобы узнать секреты взаимодействия групп функциональных блоков в параллельных конвейерах.
От CDC 6600 «Эльбрус» позаимствовал архитектуру множественных функциональных блоков (всего 10): сумматор, умножитель, делитель, логический блок, блок преобразования BCD-кодировки, блок вызова операнда, блок записи операнда, блок обработки строк, блок выполнения подпрограмм и блок индексации.
Существует некоторое функциональное совпадение между этими блоками и контроллерами B6700, но есть и важные различия, например, арифметики в «Эльбрусе» аж 4 независимых группы, вместо одной.
Множественные АЛУ уже применялись в других машинах, но никогда в мире – на стековом процессоре. Естественно, это делалось не по причине великой тупости западных разработчиков. Стек по определению предполагает нулевую адресацию – все необходимые операнды должны лежать наверху. Очевидно, что в условиях отсутствия традиционных адресов лишь одна операция за такт может корректно обратиться к вершине – это в принципе исключает работу параллельных блоков.
Группе Бурцева пришлось чудовищно извращаться, чтобы обойти это ограничение.
По факту стековый процессор B6700 в варианте «Эльбруса» вообще перестал быть стековым! Чудес не бывает и еж с ужом не скрещивается, так что внутреннюю, невидимую программисту архитектуру, пришлось сделать классической регистровой. Устройство управления принимает и декодирует команду, как обычно, а затем преобразует ее в формат внутренних регистров. B6700 интерпретировал как внутренние регистры только 2 верхних элемента стека, «Эльбрус» же – 32 элемента! По сути, от стека там осталось одно название.
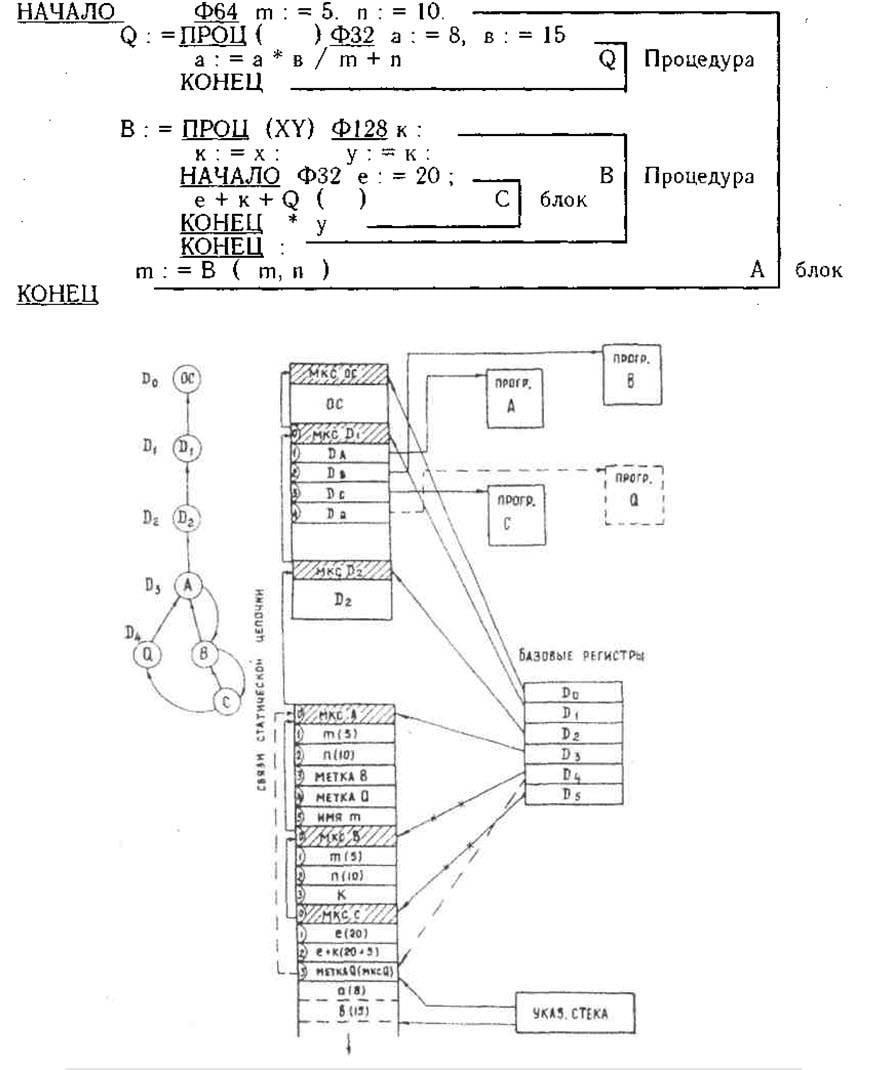
Состояние псевдостека «Эльбрус» в момент перехода к процедуре Q. Из статьи Бурцева «Принципы построения многопроцессорных вычислительных комплексов «Эльбрус».
Естественно, это было бы полностью бесполезно, если бы УУ не могло загрузить параллельно все функциональные устройства. Так был разработан механизм спекулятивного исполнения, тоже абсолютно оригинальный.
Инструкции «Эльбрус» могут быть переданы функциональным блокам до того, как будут доступны все необходимые операнды, будучи загруженными, они просто станут ожидать данных. По сути, выполнение происходит по принципу dataflow-архитектуры, точный порядок исполнения зависит от того, в каком порядке становятся доступны операнды.
Чего же добились в итоге?
Ну, реакция современного программиста на такие дикие решения очевидна:
Помню, меня убила работа с массивами. Переключаться в режим супервизора, чтобы выделить массив – это как, нормально? Это вообще нормально, что исполнительный конвейер знает про массивы? Работа с массивами через дескриптор – это что, эффективно? Выход за границы типа так быстрее проверять, да? Страшно представить, как этот ужас вообще на аппаратуру ляжет. Впрочем, тогда была другая раскладка с латентностью и скоростью работы памяти и прочих компонент, совсем не такая, как сейчас. Она могла оправдывать такие смелые ходы, но такие дизайны не живут, по-любому. Собственно, они и не выжили…
Теоретически разработчики чистых теговых машин отталкивались от того, что в середине 1970-х еще не было архитектур и компиляторов, способных хоть на какое-то автоматическое распараллеливание кода, в результате чего, большая часть многопроцессорных систем не могла быть эффективно загружена полностью, и исполнительные блоки часто простаивали. Выходом из этого тупика стала суперскалярная архитектура или же пресловутые VLIW-машины, но до них еще было далеко (хотя первый суперскалярный процессор был применен тем же Крэем в CDC6600 еще в 1965 г., массовостью тут пока и не пахло). Так и родилась идея облегчить труд программиста, переведя архитектуру на ЯВУ. Однако стоит отметить, что на стековой архитектуре хороший суперскаляр сделать вообще не просто – для систем команд RISC он делается гораздо проще. Давайте посмотрим, что за суперскаляр в «Эльбрус-2»: «Темп обработки команд в устройстве управления может колебаться от двух команд за 1 такт до одной команды за 3 такта. С максимальным темпом обрабатываются наиболее распространенные сочетания команд: считать величину и арифметическая команда; загрузить адрес и взять элемент массива; загрузить адрес и записать».
В результате мы имеем, то, что имеем – суперскаляр на две инструкции за такт, причем примитивнейшие инструкции. Гордиться тут нечем, хорошо хоть чтение данных умеют на арифметику накладывать (и то при попадании в кэш).
Теоретически разработчики чистых теговых машин отталкивались от того, что в середине 1970-х еще не было архитектур и компиляторов, способных хоть на какое-то автоматическое распараллеливание кода, в результате чего, большая часть многопроцессорных систем не могла быть эффективно загружена полностью, и исполнительные блоки часто простаивали. Выходом из этого тупика стала суперскалярная архитектура или же пресловутые VLIW-машины, но до них еще было далеко (хотя первый суперскалярный процессор был применен тем же Крэем в CDC6600 еще в 1965 г., массовостью тут пока и не пахло). Так и родилась идея облегчить труд программиста, переведя архитектуру на ЯВУ. Однако стоит отметить, что на стековой архитектуре хороший суперскаляр сделать вообще не просто – для систем команд RISC он делается гораздо проще. Давайте посмотрим, что за суперскаляр в «Эльбрус-2»: «Темп обработки команд в устройстве управления может колебаться от двух команд за 1 такт до одной команды за 3 такта. С максимальным темпом обрабатываются наиболее распространенные сочетания команд: считать величину и арифметическая команда; загрузить адрес и взять элемент массива; загрузить адрес и записать».
В результате мы имеем, то, что имеем – суперскаляр на две инструкции за такт, причем примитивнейшие инструкции. Гордиться тут нечем, хорошо хоть чтение данных умеют на арифметику накладывать (и то при попадании в кэш).
В принципе, СССР в этом смысле победил сам себя, машины Burroughs, как уже говорилось, не по тупости их архитекторов обошлись без таких изысков. Они хотели сделать чисто стековую архитектуру и сделали ее нормально.
В «Эльбрусе» от изящной простоты стека осталось одно название, при этом машина стала на порядок дороже и сложнее (какой ад был отлаживать процессор «Эльбруса», нам позже поведает человек, который этим занимался), а в производительности все равно не особо выиграла – получили помесь недостатков обоих классов машин.
В общем, это тот случай, когда лучше бы уж сперли идею, как есть, без попыток ее советизировать, то бишь расширить и углубить.
А что там было про массивы?
Бурцев и тут вставил свои 5 копеек.
В Burroughs B6700 доступ ко всем элементам массивов осуществляется косвенно, путем индексации через дескриптор массива. Это занимает дополнительный цикл. В «Эльбрусе» этот цикл решили убрать и добавили аппаратный блок предварительной выборки элементов массива в локальную кэш-память. В индексном блоке находится ассоциативная память, которая хранит адрес текущего элемента вместе с шагом в памяти.
В результате дескриптор нужен только, чтобы вытащить первый элемент массива; ко всем остальным можно обращаться напрямую. Ассоциативная память может хранить информацию о шести массивах, а вычисление адреса элемента в цикле занимает всего один цикл, элементы массива аж для 5 итераций цикла могут быть извлечены заранее.
Этим новшеством разработчики добились значительного ускорения векторных операций в «Эльбрусе» по сравнению с B6700, которая строилась как чисто скалярная машина.
Архитектура памяти тоже претерпела значительные изменения.
У B6700 не было кэша, только локальный набор регистров специального назначения. В «Эльбрусе» кэш состоит из четырех отдельных секций: буфер инструкций (512 слов) для хранения инструкций, выполняемых программой, буфер стека (256 слов) для хранения наиболее активной (самой верхней) части стека, которая в противном случае хранится в основной памяти; буфер массива (256 слов) для хранения элементов массива, которые обрабатываются в циклах; ассоциативная память для глобальных данных (1 024 слова) для данных, отличных от тех, которые хранятся в других буферах. Сюда входят глобальные переменные программы, дескрипторы и локальные данные процедур, которые не помещаются в буфер стека.
Такая организация кэша позволила эффективно включить относительно большое количество процессоров в конфигурацию с общей памятью.
В чем вообще проблема с прикручиванием кэша к многопроцессорной системе?
Дело в том, что каждый процессор может иметь свою локальную копию данных, но, если мы хотим заставить процессоры параллельно обработать одну задачу, то мы должны убедиться, что содержимое кэшей идентично.
Такая проверка называется поддержанием когерентности кэша и требует многочисленных обращений к ОЗУ, что жутко тормозит систему и убивает всю идею. Именно поэтому число процессоров в архитектуре SMP – симметричной мультипроцессорности, крайне редко превышает 4 штуки (даже в настоящее время 4 – это классическое максимальное число сокетов в серверной материнской плате).
В двухпроцессорном мейнфрейме IBM 3033 (1978) использовалась простая конструкция под названием store-through, при которой данные, измененные в кэше, сразу же изменяются в ОЗУ.
В IBM 3084 (1982, 4 процессора) использовалась более продвинутая схема поддержания когерентности, при которой передача данных в ОЗУ могла быть отложена до тех пор, пока элементы кэша не будут перезаписаны или пока другой процессор не получит доступ к соответствующим элементам данных в основной памяти.
Именно поэтому 3-х процессорный B6700 обошелся без кэша – его процессоры и так были слишком навороченными.
Когерентность кэша в «Эльбрусе» поддерживалась за счет использования понятия критической секции в программе, хорошо знакомого архитекторам ОС. Части программы, которые обращаются к ресурсам (данным, файлам, периферии), разделяемым несколькими процессорами, в момент обращения устанавливали специальный семафор, означающий вход в критическую секцию, после чего ресурс блокировался для всех прочих процессоров. После выхода из нее ресурс снова разблокировался.
С учетом того, что критические секции составляли (по крайней мере, по данным разработчика) около 1 % средней программы, 99 % времени совместное использование кэша не требовало накладных расходов на поддержание когерентности. Инструкции же в буфере инструкций по определению статичны, поэтому их копии в нескольких кэшах остаются идентичными. Это одна из причин, по которой «Эльбрус» поддерживал до 10 процессоров.
Вообще, его архитектура являет собой пример очень раннего применения сегментированного кэша, похожий принцип (буфер стека, буфер инструкций и буфер ассоциативной памяти) был реализован уже в B7700, но он вышел в 1976 году, когда большая часть работ по созданию архитектуры «Эльбруса» была завершена.
Таким образом, «Эльбрус» заслуженно получает титул одной из первых в мире систем общего назначения с разделяемой на 10 процессоров памятью.
Технически (с учетом того, что «Эльбрус-2» нормально заработал только в 1989 году) первым выпущенным суперкомпьютером такого типа стал Sequent Balance 8000 с 12 процессорами National Semiconductor NS32032 (1984 год; в 1986 вышла версия Balance 21000 с 30 процессорами), но сама идея появилась у группы Бурцева однозначно на десять лет раньше.
Модель памяти «Эльбруса» была чрезвычайно эффективна.
Например, выполнение простейшей программы в стиле сложения нескольких чисел с переприсваиванием требовало в случае S/360 от 620 обращений к памяти (если писать на ALGOL) до 46 (если на ассемблере), 396 и 54 в случае БЭСМ-6 и только 23 в «Эльбрусе».
Как и в машинах Burroughs, в «Эльбрус» используются теги, но их применение многократно расширено.
В своем рвении передать как можно больше контроля аппаратуре, группа Бурцева удвоила длину тега до 6 бит. В результате машина смогла различать операнды половинной/одиночной/двойной точности, целые/вещественные числа, пустые/полные слова, метки (включая такие специализированные штуки, как «привилегированная метка без блока внешних прерываний» и «метка без блока записи адресной информации»), семафоры, управляющие слова и другие.
Одной из основных целей создания меток было упрощение программирования. Если бы функциональные блоки могли различать вещественные и целочисленные операнды, они могли бы быть спроектированы так, чтобы адаптироваться к вычислениям на любом из них, и отпала бы необходимость в отдельных скалярных и вещественных блоках.
По сути, «Эльбрус» реализовал динамическую типизацию на уровне, сравнимом с современным ООП, причем аппаратно.
Еще одним назначением тегов было обнаружение ошибок, таких как попытка выполнить арифметическую операцию над командой, теги также могли использоваться для защиты памяти, ограничения на запись определённых данных и т. п.
В области тегов «Эльбрус» продвинул идеи базовой машины и B6700 на новый уровень сложности.
Все это позволило добиться того, чего не добились архитекторы Burroughs. Как мы помним, им потребовались отдельные расширения ALGOL для написания кода ОС и последующего управления системой. Разработчики «Эльбруса» отказались от этой идеи и создали единый полный универсальный язык «Эль-76», на котором можно было писать все.
Чтобы написать всю ОС на языке высокого уровня (включая код, отвечающий за самые низкоуровневые внутренние вещи, такие как распределение памяти и переключение процессов), необходимо специальное аппаратное обеспечение очень высокого уровня. Например, переключение процессов в ОС «Эльбрус» было реализовано как последовательность операторов присваивания, выполняющих четко определенные действия над специальными аппаратными регистрами.
Конструкция ОЗУ в обеих машинах чрезвычайно похожа, хотя «Эльбрус» (особенно во втором варианте) содержит намного больше памяти.
ОЗУ «Эльбрус» организована иерархически, секция памяти (1 шкаф) состоит из 4 модулей, каждый модуль из 32 блоков по 16 килослов. Чередование возможно на нескольких уровнях: между секциями, между модулями внутри секции и внутри отдельных модулей. За один цикл из каждого модуля памяти может быть считано до четырех слов. Максимальная пропускная способность памяти составляет 450 Мбайт/с, хотя максимальная скорость обмена данными с каждым процессором составляет 180 Мбайт/с.
Схемы управления памятью в B6700 и «Эльбруса» в общем очень похожи. Память организована в сегменты переменной длины, которые отражают логические разделы программы, определяемые компилятором. В соответствии с логическим делением программы, сегменты могут иметь различные уровни защиты и разделяться между процессами.
В B6700 сегменты перемещались между основным и виртуальным хранилищем целиком. Массивы были исключением. Они могли храниться в основной памяти группами по 256 слов в каждой, ограниченными с двух сторон словами-связками.
В «Эльбрусе» сегменты кода рассматриваются иначе, нежели сегменты данных и массивы. Код обрабатывается также, как в B6700, а данные и массивы организованы в страницы по 512 слов каждая.
Подход «Эльбруса» здесь более эффективен и позволяет быстрее выполнять подкачку.
Кроме того, в «Эльбрусе» используется более современный тип виртуальной памяти.
В компьютерах Burroughs адресация была ограничена 20 битами, или 220 словами – максимальный размер физической памяти в B6700/7700. Присутствие сегментов в основной памяти обозначалось специальным битом в их дескрипторе, который оставался в ОЗУ во время выполнения процесса. Не существовало понятия истинного виртуального пространства памяти, которое было бы больше, чем общий объем физической памяти; дескрипторы содержали только физические адреса.
Машины «Эльбрус» использовали аналогичную 20-битную схему адресации для сегментов программы, но для сегментов данных и массивов констант использовалась 32-битная адресация. Это обеспечило виртуальное пространство памяти в 232 байта (4 гигабайта). Эти сегменты перемещались между виртуальной и физической памятью с помощью механизма подкачки, который использовал таблицы подкачки, хранящиеся в ассоциативном блоке страничной памяти, для преобразования между виртуальными и физическими адресами. Виртуальные адреса состоят из номера страницы и смещения в пределах страницы. Это фактически полноценная современная реализация виртуальной памяти, такая же, как в машинах IBM.
Итак, каков наш вердикт?
«Эльбрус» однозначно не был полным клоном Burroughs B6700 (и даже B7700).
Более того, он не был даже его идеологическим клоном, скорее – братом, потому что и B6700, и «Эльбрус» были вдохновлены одним источником – работами Айлифа над базовой машиной и трудами Манчестерского университета, да и сам общий предок B-серии, знаменитый B5000, был развитием идей, заложенных в машине Райса R1. Кроме того, «Эльбрус» использовал в качестве вдохновения CDC 6600 (куда без нее) и в плане работы с виртуальной памятью – IBM S/360 model 81.
В этом отношении мы, без сомнения, признаем, что сама архитектура «Эльбруса» находилась абсолютно в тренде мировых разработок 1970-х годов и была достойным их представителем.
Более того, во многих аспектах она была куда более передовой, чем B6700/7700.
Действительно неудачным решением можно признать, пожалуй, лишь попытки достижения суперскалярности, которые провалились и с архитектурной (суперскаляр на 2–3 операции, как уже говорилось, это ни о чем и не стоит свеч), и с практической (в результате и без того чудовищно сложный процессор стал еще сложнее, занимая огромный Т-образный шкаф и почти не поддаваясь отладке, потому с ним и провозились столько лет) точки зрения.
К сожалению, чтобы обходить такие моменты, надо обладать колоссальным опытом и интуицией, вырабатываемой годами работы с лучшими мировыми образцами архитектуры, чего в Союзе, понятное дело, не было.
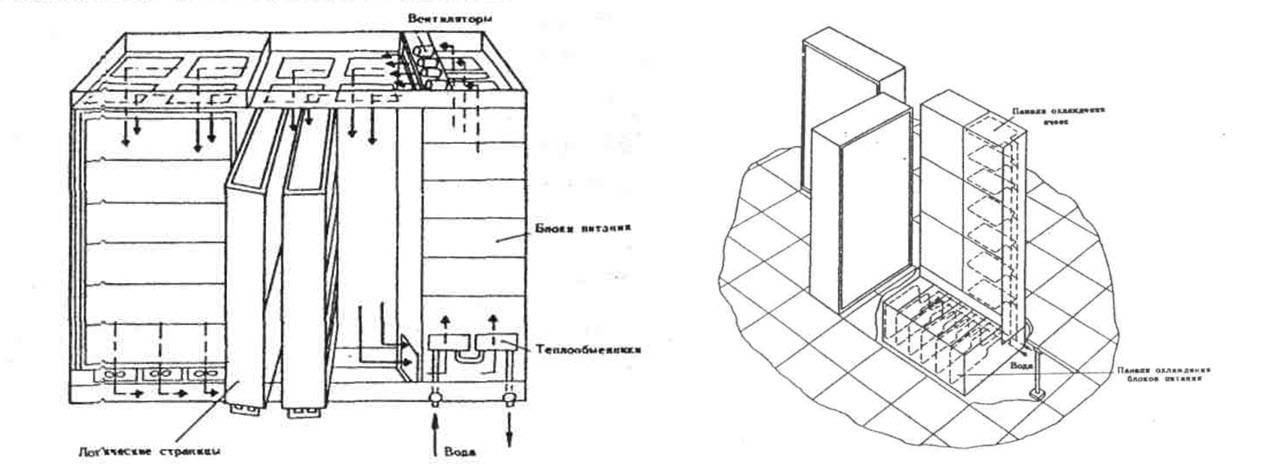
Типовой шкаф «Эльбрус-1» и ЦП «Эльбрус-2» из статьи Бурцева «Параллелизм вычислительных процессов и развитие архитектуры суперЭВМ. МВК «Эльбрус».
Естественно, не стоит говорить о какой-либо оригинальности «Эльбруса» – по сути, он представлял собой всего лишь компиляцию разнообразных технических решений, значительно улучшенных в некоторых аспектах.
Но с этой точки зрения и B5000 представлял собой сильно продвинутую версию R1, о чем мы уже говорили.
Также не стоит и вопрос об актуальности такой архитектуры сейчас – 1970-е годы давно прошли, история ИТ повернула в абсолютно другом направлении и идет туда уже 40 лет.
Итак, на бумаге «Эльбрус» по меркам 1970 года был, без преуменьшения, шедевром, вполне сравнимым с лучшими западными машинами. А вот его воплощение…
Впрочем, это тема для следующей статьи.
Продолжение следует…
Информация